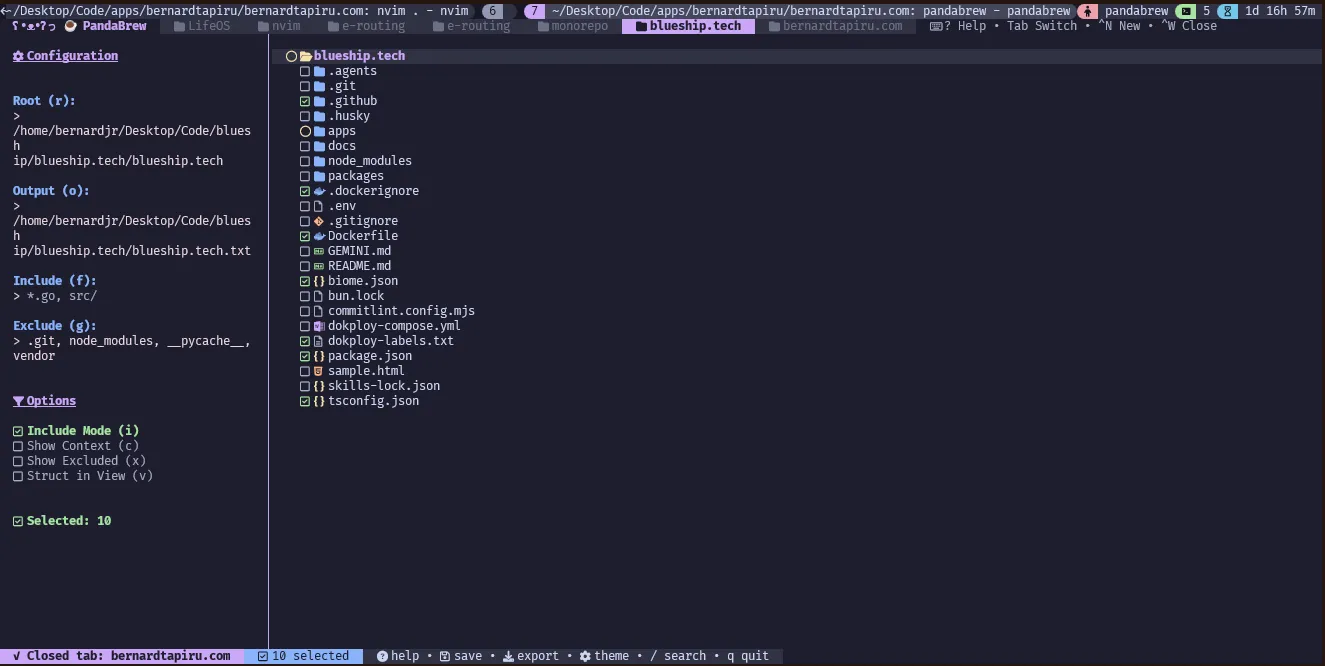
Manually copying and pasting files into LLMs is slow and error-prone. I built PandaBrew because using chat-based previews of LLMs is free and flexible between providers, but it requires a fast way to get project context. The nature of this workflow also prompts me to review every change to my files before extraction.
I chose Go because it is a balanced choice for directory traversing and file extraction while allowing me to iterate fast. I used Python for a prototype but found it harder to debug compared to Go’s test-driven toolkit. I just had to define the directory and expected results first.
The architecture provides a browser-like experience where you can manage multiple directories as tabs. This makes it easy to change contexts or projects and leave sessions in the background. It extracts per parent folder to keep the context clean.
Building the TUI with Bubbletea was difficult because making the theme changeable required painting the entire terminal with characters and computing layout shifts for different screen sizes manually.
# Headless extraction for automated context gathering
./pandabrew --headless --root ./my-project --output context.txtPandaBrew has turned a 10-minute manual task into a 5-second command, providing perfectly pruned, high-signal codebase context every time.
Source Code: GitHub Repository